자바나 코틀린을 사용하면서 언어 내부를 조사한다던지, 자료구조 성격의 클래스를 설계한다던지, 특정 계층에서만 사용할 수 있는 함수를 작성 할때 제네릭을 종종 접한다.
하지만 매번 제네릭에 대한 이해가 부족해 타입 검사기가 왜 거부하는지 이해하지 못하여 원하는대로 작성을 못한 경험이 있다.
그리고 제네릭하면 빠지지 않는 공변,불변,반공변에 대한 내용도 머리에서 정리되지 않아 누군가에게 설명하기도 힘들었다.
이번에 타입으로 견고하게 다형성으로 유연하게를 읽으면서 제네릭에 대해 구멍나있던 지식들을 촘촘히 채울 수 있었다.
(만약 이런 경험이 있는 개발자라면 이 책을 추천한다.)
이 글을 통해 아래의 내용을 학습할 수 있다.
- 여러 종류의 다형성
- 제네릭 가변성이 왜 필요한지
- PECS를 왜 지켜야 하는지
- 제네릭 가변성의 종류
일단 다형성에 대해 간단하게 알아보자.
다형성
다형성은 프로그램의 한 개체가 여러 타입에 속하도록 만드는 것이다.
(개체는 값, 함수, 클래스, 메서드 등 여러 가지가 될 수 있다.)
하나의 값이 여러 타입에 속할 수도 있고, 한 함수를 여러 타입의 함수로 사용할 수도 있는 것이다.
다형성은 거의 모든 정적 타입 언어에서만 발견할 수 있는 매우 널리 사용되는 개념이다.
"어떤 개체에 다형성을 부여하는지" , "어떻게 다형성을 부여하는지" 를 이해하는 것이 중요하다.
서브타입에 의한 다형성
이 주제는 객체를 다룰 때 유용하며 서브타입 이라는 개념을 통해 다형성을 실현한다.
서브타입은 타입 사이의 관계이며, "A는 B이다." 라는 설명이 올바르다면 A는 B의 서브타입 , B는 A의 슈퍼타입이다.
A는 B의 서브타입일 때 B 타입의 부품을 A 타입의 부품으로도 간주할 수 있게 하는 기능이 서브타입에 의한 다형성이다.
즉, 슈퍼타입이 요구되는 자리에 서브타입이 위치하더라도 타입 검사기가 문제삼지 않는다는 것이다.
반대로 서브타입이 요구되는 자리에는 슈퍼타입이 위치할 수는 없다.
open class Person(val name: String)
class Marathoner(name: String): Person(name)
fun run1(person: Person) { .. }
run1(Person(..))
run1(Marathoner(..))
fun run2(marathoner: Marathoner) { .. }
run2(Person(name)) // 컴파일 에러 !!!
run2(Marathoner(name))
오버로딩에 의한 다형성
같은 이름의 함수들을 매개변수 타입을 서로 다르게 하여 여러 개 정의하는 것이다.
fun aging(person: Person) = Person(person.age + 1)
fun aging(marathoner: Marathoner) = Marathoner(marathoner.age + 1)
aging 두 함수 중에 어느 것을 호출할지는 언어 수준에서 자동으로 결정된다.
함수 선택의 가장 기본적인 규칙은 인자의 타입에 맞는 함수를 고른다.
예제는 정수를 관리하는 Numbers 클래스와 양수의 인덱스를 따로 가지는 PositiveNumbers 클래스가 있다고 가정하자.
open class Numbers(val elements: List<Int>)
class PositiveNumbers(elements: List<Int>): Numbers(elements) {
val positiveNumberIndexes: List<Int> = .. // 합계를 빠르게 계산하기 위해 양수의 index를 저장
}
fun positiveNumberSum(numbers: Numbers): Int = ..
fun positiveNumberSum(numbers: PositiveNumbers): Int = ..
// 각 타입에 맞는 함수가 실행된다.
positiveNumberSum(Numbers(..))
positiveNumberSum(PositiveNumbers(..))
// Numbers가 정적 타입, PositiveNumber가 동적 타입인 경우 정적 선택을 우선한다. (static dispatch)
val numbers: Numbers = PositiveNumbers(..)
positiveNumberSum(numbers)
오버로딩된 양수의 사이즈를 반환하는 positiveNumberSum() 함수를 확인할 수 있다.
- 인자의 타입에 맞는 함수를 고른다.
- 인자의 타입에 가장 특화된 함수를 고른다.
- 함수를 고를 때는 인자의 정적 타입을 우선으로 고려한다.
2번과 3번을 취합하면 함수는 인자의 동적 타입보다는 정적 타입을 우선 고려하며, 이 정적 타입에 가장 특화된 함수를 고른다.
이 이유로 함수 선택 시 정적 타입에 대한 이해가 없다면 버그를 발생시키기 쉽다.
버그를 방지하기 위한 방법은 B가 A의 서브타입일 때 A를 위한 함수가 이미 있다면 B를 위한 같은 이름의 함수를 추가로 정의하지 않는 것이다.
즉, 함수 오버로딩은 서로 완전히 다른 타입들의 값을 인자로 받는 함수를 정의하는 용도로 사용하는 게 좋다.
굳이 함수 오버로딩에 서브타입에 의한 다형성을 활용하여 복잡한 상황을 만들지 말자. (메서드 오버로딩도 동일하다.)
오버라이딩에 의한 다형성
메서드 오버라이딩은 클래스를 상속해서 자식 클래스에 메서드를 새로 정의할 때 메서드의 이름과 매개변수 타입을 부모 클래스에 정의되어 있는 메서드와 똑같게 정의하여 자식 클래스에 특화된 방법을 정의하는 방법이다.
양수의 개수를 반환하는 Numbers의 length()함수를 최적화한 PositiveNumbers가 있다고 가정하자.
open class Numbers(val elements: List<Int>) {
open fun length(): Int = ..
}
class PositiveNumbers(elements: List<Int>): Numbers(elements) {
val positiveNumberIndexes: List<Int> = ..
override fun length(): Int = ..
}
val elements = listOf(1,2,3,4)
// 각 타입이 소유하고 있는 메서드가 실행된다.
val numbers: Numbers = Numbers(elements)
numbers.length()
val positiveNumbers: PositiveNumbers = PositiveNumbers(elements)
positiveNumbers.length()
// 오버라이딩의 경우 동적 선택 (dynamic dispatch)을 우선한다.
val numbers2: Numbers = PositiveNumbers(elements)
numbers2.length()
- 인자의 타입에 맞는 메서드를 고른다.
- 인자의 타입에 가장 특화된 메서드를 고른다.
- 메서드를 고를 때는 인자의 정적 타입을 우선으로 고려한다.
- 메서드를 고를 때는 수신자의 동적 타입도 고려한다.
오버로딩과 다르게 오버라이딩은 동적 타입에 대해 더 특화된 메서드가 선택되기 때문에, 정적 타입에 상관없이 언제나 그 특화된 동작이 사용되도록 만들 수 있다.
즉, 함수 선택은 인자의 정적 타입만 고려하지만 메서드 선택은 인자의 정적 타입도 고려하고 수신자(메서드를 호출하는 객체)의 동적 타입도 고려된다.
매개변수에 의한 다형성
매개변수에 의한 다형성은 타입 매개변수를 통해 다형성을 만드는 기능으로, 제네릭스라고도 부른다.
fun <T> choose(v1: T, v2: T): T {
println(v1)
println(v2)
return if(readln() == "Y") v1 else v2
}
T를 매개변수 타입 표시와 결과 타입 표시에 사용했다. 이와 같이 한 개 이상의 타입 매개변수를 가지는 함수를 제네릭 함수라고 부른다.
타입 매개변수를 추가할 수 있는 곳은 함수뿐이 아니라 타입에 타입 매개변수를 추가하여 제네릭 타입을 지정할 수 있고,
타입 매개변수를 가진 클래스를 정의하여 제네릭 클래스도 만들 수 있다.
하지만 제네릭 T가 아무 타입이나 될 수 있기 때문에 특정 타입에서 제공하는 기능을 사용할 수 없다.
타입 매개변수로 지정된 타입은 함수 또는 클래스 안에서 특정 능력이 필요한 자리에 사용된다면 제네릭으로 선언할 필요가 없다.
두 다형성의 만남
다형성의 내용은 이해하기 쉬웠을 것이다. 이제 이 글을 쓴 이유인 제네릭 가변성에 대해 알아보자.
위에서 설명한 서브타입에 의한 다형성과 매개변수에 의한 다형성이 만나게 되면서 복잡한 여러 기능들이 탄생하게 되는데 순서대로 알아보자.
제네릭 클래스와 상속
abstract class List<T> {
abstract fun get(index: Int): T
}
class ArrayList<T>: List<T>() {
override fun get(index: Int): T = ..
}
위와 같은 제네릭 클래스가 있을 때 타입들 사이의 서브타입 관계가 ArrayList<T>: List<T>라면 ArrayList<A>는 List에 등장하는 모든 T를 A로 바꿔서 만든 타입의 서브타입 이라고 이해할 수 있다.
그리고 서브타입을 선언할 때 특정 타입에 대한 서브타입으로 만들수도 있다.
기존의 List<T>를 구현하는 ArrayList<T> 와 다르게 List<Boolean>() 에 대한 클래스와 함수를 필요로한다고 가정해보자.
class AnotherList: List<Boolean>() {
override fun get(index: Int): Boolean = ..
}
val stringList = ArrayList<String>()
val intList = ArrayList<Int>()
val anotherList = AnotherList()
fun <T> findFirst(list: List<T>): T = ..
fun isExist(list: List<Boolean>): Boolean = ..
findFirst(stringList)
findFirst(intList)
findFirst(anotherList)
isExist(stringList) // 컴파일 에러 !!!
isExist(intList) // 컴파일 에러 !!!
isExist(anotherList)
AnotherList와 같이 특정 타입에 대한 서브타입을 지정하여 의도를 직관적으로 표현할 수 있다.
타입 매개변수 제한
제네릭 함수를 정의한다는 것은 여러 타입으로 사용될 수 있는 함수를 만드는 일이니, 인자로 주어질 값이 특별한 능력을 가진다고 가정할 수 없다.
반대로 인자가 특별한 능력을 가져야만 한다면 그 함수는 제네릭 함수일 필요가 없다.
open class Person(private val age: Int): Comparable<Person>{
override fun compareTo(other: Person): Int = compareValuesBy(this, other, Person::age)
}
class Marathoner(age: Int): Person(age)
fun elder(person: Person, other: Person): Person =
if(person > other) person else other
val person: Person = elder(person1, person2)
val marathoner: Marathoner = elder(marathoner1, marathoner1) // [1] 컴파일 에러 !!!
[1] 컴파일 에러가 난 부분은 elder() 함수의 파라미터로 Marathoner가 사용되어도 서브타입에 의한 다형성으로 컴파일을 통과하지만 기대하는 반환 타입이 Marathoner이기 때문에 컴파일 에러가 발생한다.
실제로 반환 타입인 Person은 Marathoner의 서브타입이 아니기 때문이다.
elder 함수를 사용하기 위해 제네릭을 적용하려 할 수 있다. 하지만 제네릭 타입은 모든 타입을 수용하기 때문에 > 연산 같은 특별한 능력을 사용할 수 없다.
이때 타입 매개변수 제한의 상한(upper bound) 을 지정하여 "T가 최대 Person 타입까지 커질 수 있다." 라는 의미를 부여할 수 있다.
즉, T가 Person의 서브타입이다. 라고 선언하는 것이다. (제네릭 함수뿐 아니라 제네릭 클래스도 마찬가지다.)
fun <T: Person> elder(person: T, other: T): T =
if(person > other) person else other
val person: Person = elder<Person>(person1, person2)
val marathoner: Marathoner = elder<Marathoner>(marathoner1, marathoner1)
위와 같이 상한을 <T: Person>으로 지정하여 반환 타입으로 Marathoner를 받을 수 있고, 특별한 > 연산을 사용할 수 있게 되었다.
class List<T : Person> {
fun get(index: Int): T = TODO()
}
하지만 List<T>의 상한을 Person으로 제한했다고 해서 List<Marathoner>가 List<Person>의 서브타입이라고 보장하진 않는다.
둘 이상의 상한 제한
기본적으로 <>에 하나의 상한만 지정이 가능하지만 코틀린에서는 둘 이상의 상한이 필요한 경우 where을 사용할 수 있다.
전달된 유형은 절의 모든 조건을 동시에 만족해야한다. 아래의 예제를 확인해보자.
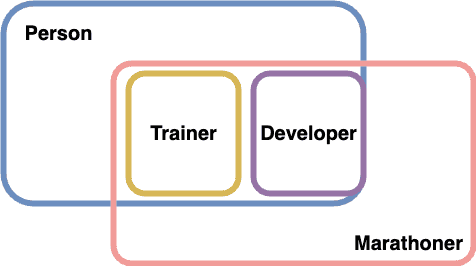
interface Person
interface Marathoner
class Trainer: Person, Marathoner
class Developer: Person, Marathoner
interface Intersection<T> where T : Person, T : Marathoner
fun main() {
val person = object : Intersection<Person> {} // 컴파일 에러 !!!
val marathoner = object : Intersection<Marathoner> {} // 컴파일 에러 !!!
val trainer = object : Intersection<Trainer> {}
val developer = object : Intersection<Developer> {}
}
Intersection<T> 인터페이스를 구현하는 타입은 Person와 Marathoner 둘 다 만족해야 한다.
아래와 같이 함수의 인자를 동시에 제한하여 CharSequence와 Comparable을 구현하는 타입만 받을 수 있는 함수를 만들수도 있다.
fun <T> copyWhenGenerator(list: List<T>, threshold: T): List<String>
where T: CharSequence, T: Comparable<T> =
list.filter { it > threshold }.map { it.toString() }
describe("copyWhenGenerator 함수는") {
val param1: Pair<List<String>, String> = listOf("a", "b", "c", "d") to "b"
val param2: Pair<List<StringBuilder>, StringBuilder> = listOf(
StringBuilder("A"),
StringBuilder("B"),
StringBuilder("C")
) to StringBuilder("B")
context("threshold 보다 큰 값만 반환한다.") {
copyWhenGenerator(param1.first, param1.second) shouldBe listOf("c" , "d")
copyWhenGenerator(param2.first, param2.second) shouldBe listOf("C")
}
}
가변성
지금까지 제네릭 함수를 정의할 때는 대개 매개변수 타입과 결과 타입의 관계를 유지해야 한다는 목표가 있었다.
아래의 choose()와 elder() 같이 받은 타입을 그대로 반환해야 하는 함수는 매개변수에 의한 다형성이 반드시 필요했다.
반면 인자로 받아 소비만하는 run()과 같은 함수는 서브타입에 의한 다형성이면 충분하다.
open class Person
class Marathoner : Person()
fun <T> choose(v1: T, v2: T): T = if ( .. ) v1 else v2
fun <T: Person> elder(person: T, other: T): T = if( .. ) person else other
fun run(person: Person) {
person.age ..
}
Marathoner는 Person의 서브타입이 맞지만, List<Marathoner>는 List<Person>의 서브타입이 아니기 때문에 List<Marathoner>와 List<Person> 타입의 리스트를 모두 사용하기 위한 함수는 averageAge함수처럼 제네릭 함수로 정의하고 타입 매개변수 제한을 사용하였다.
fun <T: Person> averageAge(people: List<T>): Int = ..
하지만 이 방법대로라면 아래와 같은 귀찮은 점이 있다.
List<A>타입의 인자를 받는 함수를 정의할 때 마다 매개변수 타입을List<A>로 하는 대신, 상한이A인 타입 매개변수T를 정의하고 매개변수 타입을List<T>로 해야 한다.- 제네릭 타입의 값을 인자로 받는 모든 함수를 동일하게 제네릭 함수로 만들어야 한다.
그럼 그냥
Marathoner가Person의 서브타입인 것처럼List<Marathoner>도List<Person>의 서브타입이면 안 될까?
즉, "B가 A의 서브타입일 때 List<B>가 List<A>의 서브타입이라고 인정해주면 안될까?"
List<Marathoner>가 List<Person>의 서브타입이 된다고 가정하고 ReadOnlyList와 ReadWriteList의 예제를 보자.
open class Person(val age: Int)
class Marathoner(age: Int) : Person(age)
// [1] 가지고 있는 원소들을 알려줄 뿐, 원소를 추가하거나 제거할 수 없는 리스트다.
abstract class ReadOnlyList<T> {
abstract fun get(index: Int): T
}
val marathoners: ReadOnlyList<Marathoner> = ..
val people: ReadOnlyList<Person> = marathoners
val person = people.get(0)
person.age ..
[1]의 상황을 보면 Marathoner의 객체들로 구성된 marathoners 리스트는 people에 대입이 가능하고, people에서 꺼낸 원소는 Person 타입으로 사용할 수 있다.
런타임에는 Marathoner 객체이지만 타입 검사기가 알 수 있는 타입은 Person이다.
하지만 이 상황은 문제가 되지 않는다. Marathoner는 이미 Person의 서브타입이므로 Marathoner 객체를 Person 객체처럼 사용해도 문제 없다.
즉, ReadOnlyList<Marathoner> 를 ReadOnlyList<Person>으로 취급함으로써 일어날 수 있는 일은 Person 객체를 기대한 곳에서 Marathoner 객체가 나오는 것 뿐이다.
// [2] 가지고 있는 원소들을 알려주고 새 원소를 추가할 수 있다.
abstract class ReadWriteList<T> {
abstract fun get(index: Int): T
abstract fun add(element: T)
}
val marathoners: ReadWriteList<Marathoner> = ..
val people: ReadWriteList<Person> = marathoners
people.add(Person(..))
val marathoner: Marathoner = marathoners.get(0)
[2]의 상황을 보면 Marathoner의 객체들로 구성된 marathoners 리스트를 people에 대입하고, people에 Person을 추가할 때 Marathoner와 Person이 같은 리스트를 나태나는 문제가 발생한다.
people에 Marathoner 객체와 Person 객체가 동시에 존재할 수 있게 되면서 marathoners에 Person 객체가 추가되게 되었다.
타입 검사기는 marathoners에서 꺼낸 원소의 타입은 Marathoner라고 믿고있지만 실제로는 Person 객체가 반환될 수 있기 때문에 타입 안전성을 깨트리는 큰 문제다.
즉, B가 A의 서브타입일 때
ReadOnlyList<B>는 ReadOnlyList<A>의 서브타입이 가능하지만,
ReadWriteList<B>는 ReadWriteList<A>의 서브타입이 불가능하다는 것이다.
원소 읽기만 허용하면
List<B>는List<A>의 서브타입이 될 수 있지만, 원소 쓰기를 허용하면 서브타입이 될 수 없다.
이 예제를 이해하면 PECS : producer-extends, consumer-super 원칙이 등장한 이유를 이해할 수 있다.
이 내용들로 알 수 있는 사실은 "어떤 제네릭 타입은 타입 인자의 서브타입 관계를 보존하지만, 어떤 제네릭 타입은 그렇지 않다." 라는 것이다.
그러므로 제네릭 타입과 타입 인자 사이의 관계를 분류할 수 있다. 이 분류를 가변성 이라고 부른다.
가변성은 제네릭 타입과 타입 인자 사이의 관계를 뜻하며, 제네릭 타입 사이의 서브타입 관계를 추가로 정의하는 기능이다.
(하나의 제네릭 타입에서 타입 인자만 다르게 하여 얻은 타입들 사이의 서브타입 관계를 만든다.)
공변
제네릭 타입이 타인 인자의 서브타입 관계를 보존하는 것이며, 타입 인자가 A에서 서브타입인 B로 변할 때 List<A> 역시 List<B>로 변한다고 말할 수 있다.
그래서 "제네릭 타입이 타입 인자와 함께 변한다"는 뜻을 담아, 이런 가변성을 공변 (convariance) 라고 부른다.
불변
제네릭 타입이 타입 인자의 서브타입 관계를 무시하는 것이며, B가 A의 서브타입이더라도 List<B>와 List<A>는 아무런 관계가 없는 것이다.
서로 다른 타입인 것이다. 따라서 "타입 인자가 서브타입으로 변해도 제네릭 타입은 서브타입으로 안 변한다"는 뜻을 담아, 이런 가변성을 불변 (invariance) 이라 부른다.
반변
반변을 이해하기 위해서는 먼저 함수와 서브타입 관계에 대해서 이해해야 한다.
open class Person
class Marathoner : Person()
fun selectBySuperType(selector: (Person) -> Person) {
val person1: Person = selector(Person())
val person2: Person = selector(Marathoner())
}
fun selectBySubType(selector: (Marathoner) -> Person) {
val person1: Person = selector(Person()) // 컴파일 에러 !!!
val person2: Person = selector(Marathoner())
}
val superTypeConsumer: (Person) -> Person = ..
val subTypeConsumer: (Marathoner) -> Person = ..
selectBySubType(superTypeConsumer)
selectBySubType(subTypeConsumer)
selectBySuperType(superTypeConsumer)
selectBySuperType(subTypeConsumer) // 컴파일 에러 !!!
(결과 타입은 서브타입 관계를 유지하기 때문에 입력으로 받는 타입에 집중하자.)
위의 예제를 보면 (Person) -> Person은 (Marathoner) -> Person의 서브타입이 가능하다.
"사람을 인자로 받을 수 있는 함수는 마라토너를 인자로 받을 수 있는 함수다." 가 성립되기 때문이다.
즉, selectBySubType 함수에 superTypeConsumer 람다가 전달 가능하다는 것이다.
하지만 그 반대인 (Marathoner) -> Person은 (Person) -> Person의 서브타입이 아니다.
"마라토너를 인자로 받을 수 있는 함수는 사람을 인자로 받을 수 있는 함수다." 가 성립되지 않는다.
즉, selectBySuperType 함수에 subTypeConsumer 람다를 전달할 수 없다는 것이다.
첫 번째 "컴파일 에러"는 함수가 하위 타입 인스턴스를 기대하는데 상위 타입 인스턴스를 전달하려고 했기 때문에 발생한다.
두 번째 "컴파일 에러"는 함수가 상위 타입 인스턴스를 기대하는데 더 구체적인 하위 타입을 처리하는 함수를 전달하려고 했기 때문에 발생한다.
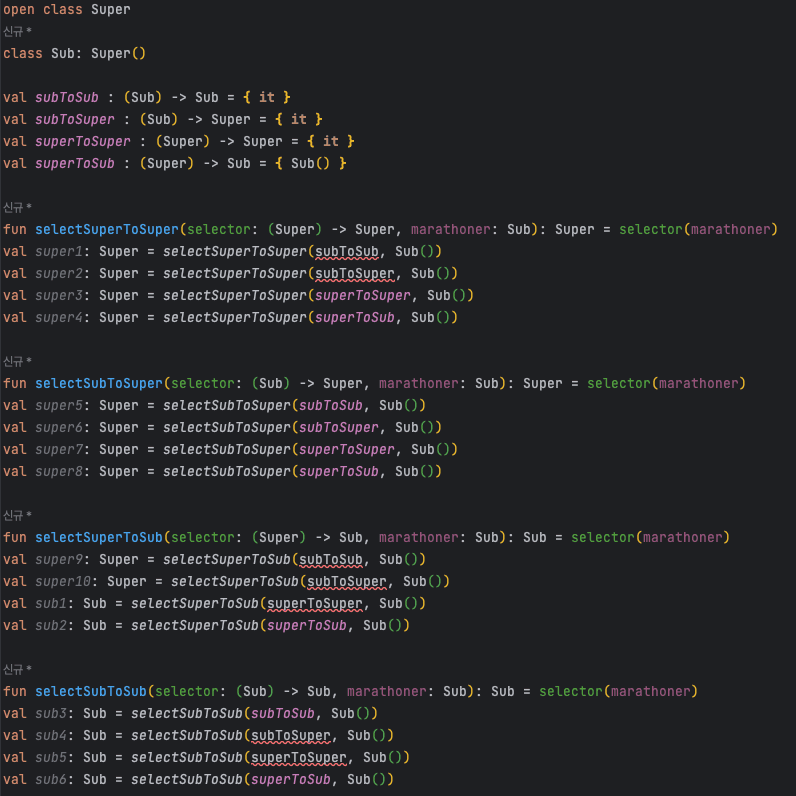
| 람다 \ 함수 인자 | selectSuperToSuper | selectSubToSuper | selectSuperToSub | selectSubToSub |
|---|---|---|---|---|
(Super) -> Super |
O | O | ❌ | ❌ |
(Super) -> Sub |
O | O | O | O |
(Sub) -> Sub |
❌ | O | ❌ | O |
(Sub) -> Super |
❌ | O | ❌ | ❌ |
즉, A가 B의 서브타입일 떄 B → C가 A → C의 서브타입이며 그 반대는 성립하지 않는다. 따라서 함수 타입은 매개변수 타입의 서브타입 관계를 뒤집는다.
결과 타입의 서브타입 관계가 유지된다는 사실(반환 타입의 공변성)은 나름 직관적인것에 비해, 매개변수 타입의 서브타입 관계가 뒤집히는게(매개변수의 반공변성) 이상할 수 있지만 논리적으로 타당하다.
selectSubToSuper의 함수는 4가지의 람다를 모두 허용하는 이유가 "함수 타입은 매개변수 타입의 서브타입 관계를 뒤집고 결과 타입의 서브타입 관계는 유지하기 때문이다." ⭐️
즉, 함수의 결과 타입과 실제 결과 타입 사이의 관계는 공변이다. 한편 함수 매개변수 타입과 실제 매개변수 타입 사이의 관계는 공변도 불변도 아니다.
여기서 제네릭 타입이 타입 인자의 서브타입 관계를 뒤집는 가변성이 등장한다.
✋ 잠깐, 왜 함수의 매개변수에 대해서는 반공변성이 적용될까?
리스코프 치환 원칙에 따르면 "서브타입은 슈퍼타입을 대체할 수 있어야 한다."
(Super) -> Super가 필요한 자리에(Sub) -> Super를 사용할 수 있어야 한다면(Sub) -> Super는Super도 처리할 수 있어야 한다.
하지만 실제로는 더 구체적인 타입인Sub가 더 일반적인 타입인Super를 처리할 수 없기 때문에 서브타입 함수가 슈퍼타입 함수처럼 사용되기 위해서는 매개변수의 타입이 더 일반적이어야 한다.
결과 타입을 C로 고정할 때 B가 A의 서브타입이면 B → C는 A → C의 슈퍼 타입이다.
타입 인자가 A에서 서브타입인 B로 변할 때 A → C는 타입 인자와는 반대 반향으로 움직여 슈퍼 타입인 B → C로 변한다고도 할 수 있다.

종합해보자면 ReadOnlyList는 원소 타입에 대해 공변 이며, ReadWriteList는 불변 이다.
마지막으로 함수 타입은 매개변수 타입에 대해서는 반변 이고, 결과 타입에 대해서는 공변 이다.
각 제네릭 타입의 가변성을 결정하는 일반적인 방법
논의를 간단하게 만들기 위해 타입 매개변수가 하나뿐인 제네릭 타입만 고려한다.
제네릭 타임의 이름은 G, 타입 매개변수의 이름은 T라고 하자.
G가T를 출력에만 사용하면 공변 , 입력에만 사용하면 반변 , 출력과 입력 모두에 사용하면 불변 이다.
G에 해당하는 타입 |
T를 출력에 사용 |
T를 입력에 사용 |
가변성 |
|---|---|---|---|
| ReadOnlyList<T> | O | ❌ | 공변 |
| ReadWriteList<T> | O | O | 불변 |
| Int -> T | O | ❌ | 공변 |
| T -> Int | ❌ | O | 반변 |
즉, 타입 매개변수를 출력에만 사용하는지, 입력에만 사용하는지, 둘 모두에 사용하는지 보면 가변성을 판단할 수 있다.
타입 매개변수를 사용한 곳에 따라 달라진다는 것이다.
정의할 때 가변성 지정하기
가변성은 각 제네릭 타입의 고유한 속성이다. 따라서 제네릭 타입을 정의할 때 가변성을 지정하는게 가장 직관적이다.
개발자는 제네릭 타입의 각 매개변수에 가변성을 표시함으로써 공변, 반변, 불변 중 하나를 고를 수 있다.
불변
abstract class List<T> {
abstract fun length(): Int
abstract fun get(index: Int): T
abstract fun add(element: T)
}
공변
abstract class ReadOnlyList<out T> {
abstract fun get(index: Int): T
}
val marathoners: ReadOnlyList<Marathoner> = ..
val people: ReadOnlyList<Person> = marathoners
val person = people.get(0)
fun averageAge(people: ReadOnlyList<Person>): Int = ..
averageAge(marathoners)
averageAge(people)
ReadOnlyList<out T>는 해당 타입 매개변수가 출력에만 사용됨을 뜻하며 원소를 추가할 수 없는 대신 공변인 리스트를 정의할 수 있다.
T를 출력에만 사용한다고 했으니, T를 메서드 결과 타입으로 사용할 수 있는 있어도 매개변수 타입으로 사용할 수는 없다.
ReadOnlyList는 공변이므로 타입 인자의 서브타입 관계를 보존한다.
이제 averageAge 함수를 제네릭 함수로 만들지 않고 타입 매개변수 제한없이 사용할 수 있다.

abstract class ReadOnlyList<T> {
abstract fun get(index: Int): T
}
위와 같이 선언된 List는 원소를 추가할 수도 없는 주제에 불변이기까지 한 불편한 리스트일 뿐이다.
T를 입력에 사용하는 메서드를 추가하려고 계획 중인 게 아니라면, 굳이 이런 리스트를 정의할 필요는 없다.
반변
abstract class Map<in K, V> {
abstract fun size(): Int
abstract fun get(key: K): V
abstract fun add(key: K, value: V)
}
타입 매개변수를 반변으로 만들고 싶을 때는 in을 붙여 그 타입 매개변수를 입력에만 사용한다는 뜻이다.
abstract fun getKey(value: V): K 이 메서드는 컴파일 에러를 발생시킨다.
Map<in K, V> 클래스는 두 개의 타입 매개변수를 가지며, in으로 가변성이 지정된 K는 get()과 add()에서 입력으로만 사용되었기 때문에 반변 으로 정의해도 타입 검사기가 문제 삼지 않는다.
반면 V는 get()에서는 출력, add()에서는 입력으로 사용되었기 때문에 반드시 불변이어야 한다.
열쇠 타입에 대해 반변이므로 B가 A의 서브타입일 때 Map<A, V>가 Map<B, V>의 서브타입이다.
예를 들면 Map<Person, Int>가 Map<Marathoner, Int>의 서브타입이다.
val personKey: Map<Person, Int> = ..
personKey.add(Person(10), 1)
personKey.add(Marathoner(10), 1)
val marathonerKey: Map<Marathoner, Int> = ..
marathonerKey.add(Person(10), 1) "컴파일 에러"
marathonerKey.add(Marathoner(10), 1)

정의할 때 가변성을 지정하는 방법은 이해하기 쉬운 대신 클래스를 정의할 때 큰 제약이 생긴다는 문제가 있다.
타입을 공변으로 만든다면 타입 매개변수를 입력에 사용하는 절반을 모두 포기해야 하고, 반변으로 만든나면 나머지 절반을 포기해야 한다.
그러니 공변이나 반변을 선택하면 반쪽짜리 클래스를 만들 수 밖에 없는 것이다.
함수형 프로그래밍에서는 대부분의 경우 수정할 수 없는 자료구조만 사용해 프로그램을 작성하기 때문에 함수형 언어에서는 이 단점이 상대적으로 덜 드러난다.
사용할 때 가변성 지정하기
제네릭 타입을 사용할 때 가변성을 지정하는 경우, 제네릭 타입을 정의할 때는 가변성을 지정할 수 없다.
모든 제네릭 타입은 불변으로 정의되며 타입 매개변수를 아무 데서나 사용할 수 있다.
불변
abstract class ReadWriteList<T> {
abstract fun length(): Int
abstract fun get(index: Int): T
abstract fun add(element: T)
}
공변
val onlyReadPeople: ReadWriteList<out Person> = ..
val size = onlyReadPeople.length()
val person: Person = onlyReadPeople.get(0)
onlyReadPeople.add(Person(10)) "컴파일 에러"
onlyReadPeople은 출력 기능만 사용할 수 있고, 원소 타입이 매개변수 타입으로 사용되지 않는 메서드만 사용할 수 있다는 뜻이다.
그리고 "A를 출력과 입력에 모두 사용할 수 있는 불변 List<A>는 A를 출력에 사용할 수 있는 리스트다." 가 사실이기 때문에 List<A>는 List<out A>의 서브타입이다.
ReadWriteList<T>는 불변이지만 ReadWriteList<out Person>는 공변이다. 따라서 B가 A의 서브타입일 때 List<out B>는 List<out A>의 서브타입이다.
fun averageAge(people: ReadWriteList<out Person>): Int {
people.get(0)
people.add(Person(10)) "컴파일 에러"
}
val onlyReadPeople: ReadWriteList<out Person> = ..
averageAge(onlyReadPeople)
val onlyReadMarathoners: ReadWriteList<out Marathoner> = ..
averageAge(onlyReadMarathoners)
val readWriteMarathoner: ReadWriteList<Marathoner> = ..
averageAge(readWriteMarathoner)

averageAge() 함수와 같이 새로운 <out Person> 타입을 통해 함수 내부에서는 출력의 용도로만 사용하겠다고 선언하여 공변으로 지정하여 사용할 수 있다.
반변
ReadWriteList<in A> 역시 ReadWriteList<A>와 비슷하게 A 타입의 원소들로 구성된 리스트를 나타내지만 입력 기능만 사용할 수 있다는 차이가 있다.
정확히 말하면 메서드 중 원소 타입이 결과 타입으로 사용되지 않는 메서드만 사용할 수 있다.
val readWritePeople: ReadWriteList<in Person> = ..
val people: Any? = readWritePeople.get(0)
readWritePeople.add(Person(10))
readWritePeople.add(Marathoner(10))
val readWriteMarathoners: ReadWriteList<in Marathoner> = ..
val marathoner: Any? = readWriteMarathoners.get(0)
readWriteMarathoners.add(Marathoner(10))
"A를 출력과 입력에 모두 사용할 수 있는 불변 List<A>는 A를 입력에 사용할 수 있는 리스트다." 가 사실이기 때문에 List<A>는 List<in A>의 서브타입이다.
따라서 B가 A의 서브타입일 때 List<in A>는 List<in B>의 서브타입이다.
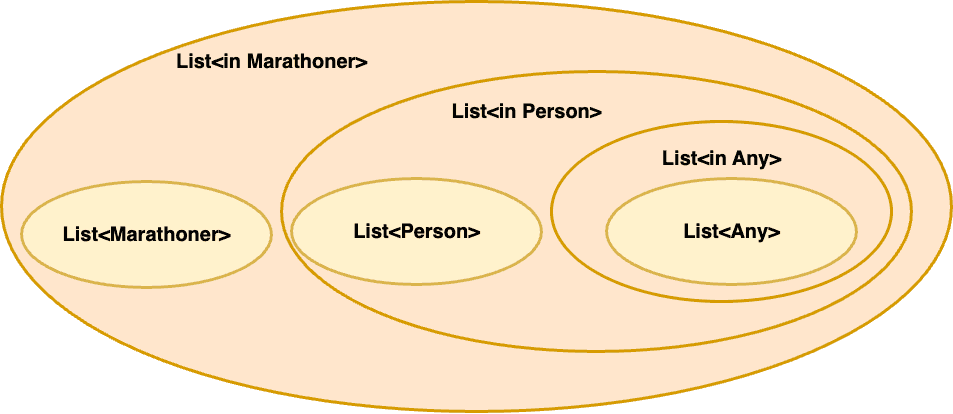
fun addPerson(people: ReadWriteList<in Person>) {
people.add(Person(..))
people.add(Marathoner(..))
}
val readWritePeople1: ReadWriteList<in Person> = ..
val readWritePeople2: ReadWriteList<Person> = ..
addPerson(readWritePeople1)
addPerson(readWritePeople2)
val readWriteMarathoners1: ReadWriteList<in Marathoner> = ..
val readWriteMarathoners2: ReadWriteList<Marathoner> = ..
addPerson(readWriteMarathoners1) "컴파일 에러"
addPerson(readWriteMarathoners2) "컴파일 에러"
addPerson 함수는 ReadWriteList<in Person> 반변으로 지정되어 있기 때문에 ReadWriteList<Marathoner>는 Person의 서브타입이긴 하지만 addPerson의 인자로 사용될 수 없다.
fun addMarathoner(people: ReadWriteList<in Marathoner>) {
people.add(Person(..)) "컴파일 에러"
people.add(Marathoner(..))
}
val readWritePeople1: ReadWriteList<in Person> = ..
val readWritePeople2: ReadWriteList<Person> = ..
addMarathoner(readWritePeople1)
addMarathoner(readWritePeople2)
val readWriteMarathoners1: ReadWriteList<in Marathoner> = ..
val readWriteMarathoners2: ReadWriteList<Marathoner> = ..
addMarathoner(readWriteMarathoners1)
addMarathoner(readWriteMarathoners2)
ReadWriteList<in Marathoner> 반변으로 지정하면 List<Person>은 List<in Marathoner>의 서브타입이기 때문에 addMarathoner 함수 호출이 다 가능해진다.
List<in Marathoner>에는 Marathoner가 보장되어야 하기 때문에 더 작은 의미를 가지는 Person을 직접 추가하지는 못한다.
이는 Person 리스트에 Marathoner 객체를 추가해도 괜찮고 Marathoner 리스트에 Person 객체를 추가하지 못한다는 직관과 일치한다.
맺으며
여러 종류의 다형성을 이해하고 제네릭 가변성에 대해 알아보았다.
사용하는 언어가 공변성과 반공변성을 어느 정도로 지원하는지를 정확하게 이해한 후 사용해야 한다.
예를들어 자바는 리턴 타입 공변성을 지원하지만 C#은 리턴 타입 공변성을 지원하지 않기 때문이다.
개인적으로 공변,불변을 제외한 나머지를 반변이라고 설명하는 글들을 많이 접했었는데 이 책에서는 반변을 설명할 때 함수와 서브타입에 대한 설명이 독특했다.
"함수 타입은 매개변수 타입의 서브타입 관계를 뒤집는다." 는 사실이 반변을 이해할 때 도움이 되었다.
어려운 제네릭 가변성에 대한 내용을 배워봤지만 제네릭이 능사는 아니다.
서브타입 관계를 추가하는 대신 기능이 빠진 타입을 만들거나, 기능을 다 갖춘 타입을 만드는 대신 서브타입 관계를 포기하거나, 개발자는 반드시 이 둘 중 하나를 골라야 한다.